你已經學會了如何在 n8n 中建立一個能抓取單一網頁的爬蟲。但真正的挑戰,往往發生在你試圖將規模從「1」擴大到「100」甚至「1000」的時候。
想像一下,你準備了一個包含 500 個商品 URL 的列表,準備將它們全部餵給你的爬蟲工作流。你滿懷信心地按下執行,結果卻遇到了災難性的後果:
- 記憶體崩潰 (Memory Crash): n8n 實例因為一次性試圖處理 500 筆資料而記憶體耗盡,整個流程直接崩潰。
- 速率限制 (Rate Limit): 你的爬蟲在成功抓取了前 50 個頁面後,開始收到大量的
429 Too Many Requests錯誤,最終被目標網站的伺服器徹底封鎖。
這些問題,都是從「單點抓取」邁向「大規模爬取 (Large-Scale Scraping)」時必然會遇到的效能與穩定性瓶頸。而解決這一切問題的核心鑰匙,就藏在 n8n 一個看似簡單、實則極其強大的節點之中——Split In Batches。
這篇文章將是你的 n8n 大規模爬蟲終極指南。我們將深入解析 Split In Batches 節點如何成為你爬蟲流程的「流量管制閥門」,並手把手教你如何利用它來解決記憶體問題、完美應對速率限制,讓你能夠充滿信心地處理數百、甚至數千個爬取目標。
當爬蟲從「單點」走向「全面」:大規模抓取遇到的兩大瓶頸
在我們深入解決方案之前,必須先清楚地認識到,當處理的 URL 數量從個位數變成百位數時,你的工作流會面臨兩種截然不同的壓力。
瓶頸一:記憶體壓力 (Memory Pressure)
n8n 的自動迴圈機制雖然方便,但它的運作方式是:上一個節點會一次性地將所有 500 筆 URL 資料(500 個 Items)全部載入到記憶體中,然後再傳遞給下一個節點。如果每個後續步驟(例如 Browserless)都需要耗費一定的記憶體來處理單筆資料,那麼 500 筆資料同時在記憶體中排隊等待處理,就很容易瞬間榨乾你伺服器的所有 RAM,導致整個 n8n 服務崩潰。
瓶頸二:請求壓力 (Request Pressure)
即使你的伺服器記憶體夠大,能夠承受 500 筆資料,但 n8n 的極高執行效率,會讓它在幾秒鐘內,就將這 500 次的爬取請求,如洪水般地全部發送到目標網站的伺服器。這將 100% 觸發我們在「Rate Limit 指南」中提到的速率限制,導致你的 IP 被封鎖。
你的 n8n 流量管制閥:Split In Batches 節點的核心原理
Split In Batches 節點,就是為了解決上述兩個問題而生的。它的中文直譯是「分割成批次」,其核心功能也正如其名:將一個包含大量 Items 的巨大資料流,切割成數個規模較小、可被輕鬆管理的「批次 (Batch)」。
你可以把它想像成一個水庫的閘門。上游的水庫(你的目標 URL 列表)一次性釋放了 500 萬噸的水(500 個 Items),如果直接衝向下游,將會引發洪水(記憶體崩潰與 Rate Limit)。Split In Batches 節點的作用,就是在中間建立一個調節閘門,讓水流能夠一批一批地、有控制地、平穩地流向下游。
這個節點的核心設定只有一個:Batch Size (批次大小)。它決定了「每個小隊伍要有多少人」,也就是每一批要包含多少筆資料。
實戰演練一 (效能優化):批次處理模式,穩定抓取大量數據
讓我們來解決第一個問題:記憶體崩潰。
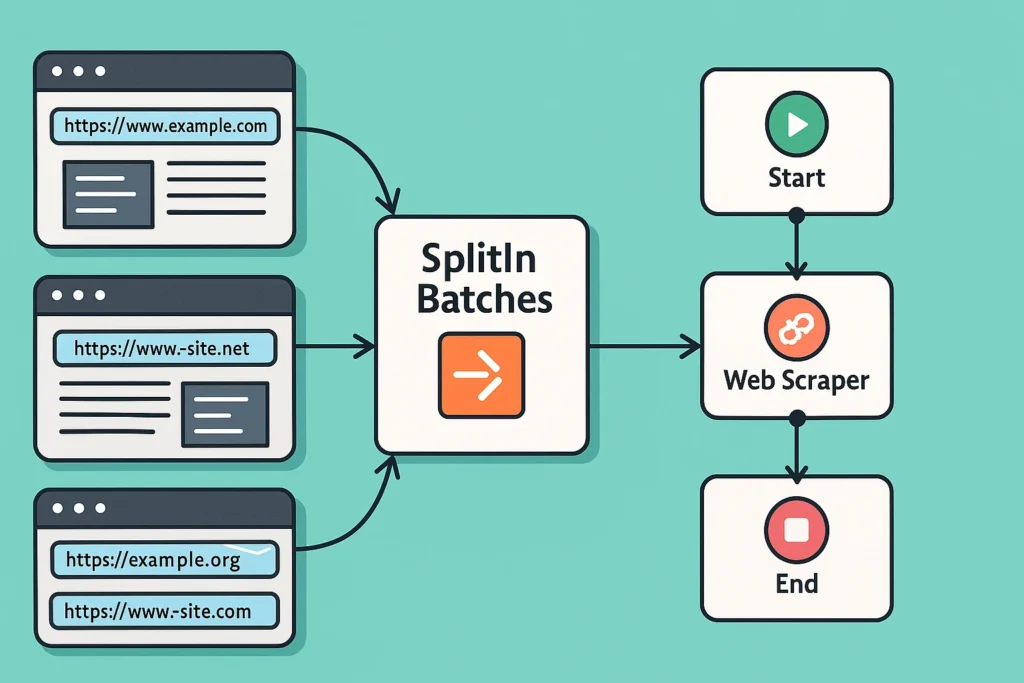
- 目標: 我們有一個包含 1000 個 URL 的列表,需要逐一抓取。我們希望 n8n 一次只在記憶體中處理 10 筆資料。
- 流程設計:
Set (準備 URL 列表)->Split In Batches->HTTP Request->...
Set節點:- 建立一個名為
urls的陣列,裡面包含了 1000 個網址。
- 建立一個名為
Split In Batches節點:- Field to Split Out:
{{ $json.urls }}(告訴節點我們要對urls這個陣列進行分割)。 - Batch Size:
10。 - 解說: 這個節點執行後,會將原本的 1 個 Item(包含 1000 個 URL),轉換成
1000 / 10 = 100個新的 Items。每一個新的 Item,都包含了一個items欄位,裡面存放著 10 筆 URL 資料。
- Field to Split Out:
- 下游的爬蟲邏輯 (
HTTP Request等):- 現在,下游的節點會執行 100 次(因為有 100 個批次)。在每一次執行中,它們處理的都只是 10 筆資料,記憶體負擔極小,從而徹底避免了崩潰的風險。正如我們在「n8n 效能優化」中所強調的,批次處理是處理大規模數據的基礎。
實戰演練二 (穩定性):結合 Wait 節點,完美應對速率限制
現在,讓我們來解決第二個問題:IP 被封鎖。
- 目標: 爬取 500 個頁面,目標網站的速率限制是「每分鐘 60 次請求」。
- 流程設計:
...->Split In Batches->Wait->HTTP Request->...
Split In Batches節點:- Batch Size: 我們可以設定為
60(或一個更保險的數字,如50)。
- Batch Size: 我們可以設定為
Wait節點:- 在
Split In Batches和HTTP Request之間,插入一個Wait節點。 - Time:
60 - Unit:
Seconds
- 在
運作解析: 這個工作流會這樣執行:
Split In Batches先放出第一批 50 筆 URL。- 這 50 筆資料流向下一個
Wait節點,整個流程在此暫停 60 秒。 - 60 秒後,流程繼續,
HTTP Request節點開始高速處理這 50 筆 URL 的抓取。 - 當這 50 筆全部抓完後,流程回到
Split In Batches,放出第二批 50 筆 URL,再次進入Wait節點暫停 60 秒… - 如此循環,我們就完美地將請求頻率,控制在了「每分鐘 50 次」的安全範圍內。
進階技巧:Batch Size 為 1 的「逐一執行」模式與錯誤處理
當你將 Batch Size 設定為 1 時,Split In Batches 就會化身為一個嚴格的「For-Each 迴圈」控制器。它會確保你的 500 個 URL,是一筆一筆、按順序地被下游節點處理。
何時使用?
- 順序敏感的任務: 當後一筆資料的處理,必須等待前一筆完成時。
- 更精細的延遲控制: 如果你想在每一次請求之間,都加入一個微小的延遲(例如 0.5 秒),你就必須使用
Batch Size: 1的模式。
搭配錯誤處理: 在 Split In Batches 的迴圈中,如果其中一筆 URL 抓取失敗,預設會導致整個工作流中斷。最佳實踐是,在迴圈內部的 HTTP Request 節點上,啟用錯誤處理。這樣,即使第 100 個 URL 抓取失敗,n8n 也可以記錄下這個錯誤,然後繼續處理第 101 個 URL,確保整個大規模抓取任務的完整性。
結語
Split In Batches 節點,是 n8n 中將簡單爬蟲,升級為規模化、工業級數據採集系統的關鍵樞紐。它看似只是一個簡單的分批工具,實則是你用來管理記憶體效能與請求穩定性這兩大核心資源的瑞士刀。
掌握了 Split In Batches 的批次處理與流量控制技巧,你就再也不會因為目標數量龐大而感到畏懼。無論是數百個商品頁面、數千篇社群貼文,還是上萬筆 API 資料,你都能夠透過設計一個穩健的批次迴圈,讓你的 n8n 爬蟲大軍,有條不紊地、可靠地、24 小時不間斷地為你完成任務。
更多精選文章請參考
n8n 與 Zapier 比較:該選哪個?2025年最完整功能、費用、優缺點分析
開源自動化工具推薦:從工作流程到測試,找到最適合你的免費方案
n8n 發送 Email 超詳細教學:從 SMTP 設定到 Gmail 節點串接,一篇搞定!
n8n Notion 串接終極指南:2025 年打造自動化工作流程,效率翻倍!